High-Performance Computing Center Stuttgart

Many engineering applications deal with multiscale problems. They are like the famous butterfly effect, where small, localized changes can have large impacts across distance and time. This means, for example, that when simulating an airplane in flight you would like to use a very fine computational mesh – ideally, surrounding the entire aircraft in virtual 1 mm cubes – to simulate at high precision how a compressible turbulent flow interacts with the plane. In practice, however, a simulation at that scale would take far too long, even with HLRS’s Hawk supercomputer or next-generation systems like Hunter or Herder. Instead, we reformulate the problem and resolve it to an intermediate scale, sometimes called the mesoscale.
Approximating in this way means that information is lost, and so to make such a simulation useful, you need a model to account for the fine-scale effects that you don’t capture. This is sometimes called scale bridging or closure modeling. To take a simple example, a colleague simulated how people evacuate a football stadium. You can essentially model people’s movements like a flow of water, and although it’s easy enough to model a smooth stream out of the building, it is hard to model individual people bumping into one another. This is important, though, because a single interaction between two people at a doorway could block an exit. To account for this, his closure model involved using Gaussian noise to recover these fine-scale effects. We do a similar thing when simulating compressible flows.
All engineering problems can be described by applying the laws of physics. To do so, we use complicated mathematical expressions that can only be solved using a supercomputer, which is why we need HLRS. Over the years, people have tried to find closure models for turbulence based on mathematical and physical reasoning. Essentially, we want to condense this complex phenomenon into a single, reliable number that can be input into a flow solver. However, there is still no clear and consistent model that represents turbulent flow in all cases. Instead, there are many models, and every researcher has his or her favorite.
Deriving such models is precisely what machine learning should be good at, and beginning a few years ago people started using it to extract low-dimensional features from high-dimensional data sets. The idea is that if we have enough data that have been generated by the process we are trying to model, then all of the necessary information about physical laws should be embedded in the data.
While it is true that nature will always obey physics, the problem with machine learning is that it does not directly replicate this data, but can only make approximations based on the data on which it is trained. For very specific cases, you can use machine learning to build astonishingly accurate models. For engineering applications, though, we want machine learning models that don’t just reproduce what we measured, but also give us reliable answers in situations for which we did not provide data.
From my perspective, and I have been guilty of this as well, we’ve put a little bit too much emphasis on saying it’s all in the data. Because machine learning uses a black box approach, there is currently no consistent way of making sure that if you use it, the answer you get doesn’t violate a basic law of physics. In the case I described earlier, the fact that two people will not merge together when they bump into each other is a physical law, but a neural network doesn’t know that and there is no guarantee that it will enforce the corresponding physical constraints. Or to take an example from aerospace engineering, it is important that your machine learning algorithm knows that gravity points straight down, and not at a slight angle. A naïve algorithm can’t necessarily know this just from the data, though.
During training, all that machine learning models see is the neighborhood of their data. Often, however, we don’t know what situations these models will actually be confronted with when we use them. When you need to apply your model to data from the next town, so to speak, we need models that contain physical constraints. With physical constraints we know that the model understands that gravity is always the same here as it is there.
A couple of years ago, people were optimistic that we wouldn’t have to do simulation anymore, but just machine learning. What we see now, however, is that we have to shift from purely data-driven models to physics-consistent models that are data-augmented or data-informed. The models should be based in physics and the data should help us to nudge them in the right direction. The approach that my lab is using is to keep the original simulation methods, but to use machine learning as an augmentation device that replaces some parts of the equation, where we know what the physical properties are.
In an approach called Relexi, which we developed at HLRS in collaboration with staff at Hewlett Packard Enterprise, we combine traditional simulation approaches and machine learning in a single method. This is because in an aircraft turbine, for example, there is very slow flow, hot flow, cold flow, and it could contain water or steam. The physics is very sensitive to tiny changes. The dimensionality of the problem is huge, making it nearly impossible to come up with long lists of data tables that tell the machine learning algorithm, “If you see this, output that.” You would have to have so much data for so many different situations.
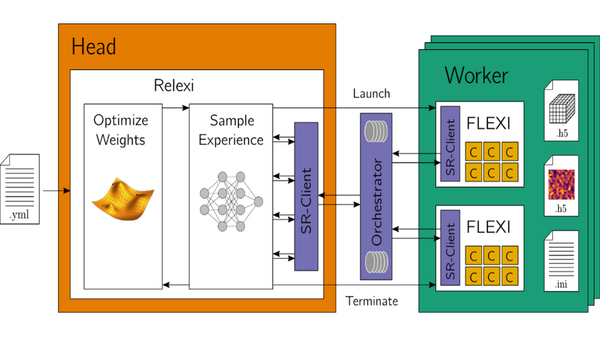
Instead, we continue to use a high-order flow solver called FLEXI that we’ve used for a long time, but it now also includes a model based on reinforcement learning. This requires running the flow solver with a machine learning model in the loop. The machine learning model recognizes what actions the solver took and what the results were. This requires an efficient HPC implementation – the solver runs on the CPU, the machine learning model on the GPU, and both have to communicate constantly and exchange data about the learning process, the current model, and the observed results. I run my solver with my untrained machine learning model in place and check the output to see if it is what I expect. If it’s not, the machine learning model improves itself.
This process is similar to how someone learns to ride a bike. If you sit on a bike for the first time and try to pedal, you will fall over, but even with the first pedal stroke you sense that you did something correctly. You can then improve upon that strategy and repeat it until after several attempts you can ride without falling. To think about this in terms of a physical model, the simulation would include components of the system describing the bike’s configuration, gravity, and your physiology. The machine learning part would use this basic information to learn how to move your joints. This is also the method that people usually use to train robots or self-driving cars.
The AI revolution in the last 10 years only came about because the mathematical operations they need to do are perfectly aligned for the GPU. Relexi has already been running on the AI components of Hawk, so we have already made good use of different architectures and are aware of the different strengths that they offer. For us, it will be great to have both code and machine learning on the GPU already.
The upcoming GPU-accelerated architecture at HLRS is also an exciting opportunity because the increase in computing power means that our code will run two orders of magnitude faster. This, in turn, means that the types of problems we will be able to tackle have grown by two orders of magnitude.
To make flying more sustainable, for example, the airplane of the future will look very different than what we are used to. Predicting the flow physics over such configurations to the level that we need is not possible, and we still work with approximation methods. Herder, or maybe even Hunter, will allow us to compute challenging flow situations across the whole wing of an aircraft to a degree that is currently not possible. This could also help to better predict flow situations when conditions become dangerous, for example when you fly too fast or things go wrong for physical reasons.
We are aware that porting to the new structure of Hunter and Herder will be a challenge. We have to refactor most of our code, rethink most of the data structures, and rethink all of the loops, which take effort and time. The benefit, though, is that it will dramatically increase the size of the computations we can do.
In any case, we are excited about the opportunities provided by the new generation of machines at HLRS. We will be able to achieve results faster and at a lower economic footprint. It is an exciting time for aerospace engineering at the moment and new ideas and architectures are being explored at a great pace; for example, NASA’s X59 supersonic demonstrator and the push towards electrified flying. We need simulation tools that can keep pace!
— Interview by Christopher Williams
A member of the Gauss Centre for Supercomputing, HLRS is one of three German national centers for high-performance computing.