High-Performance Computing Center Stuttgart

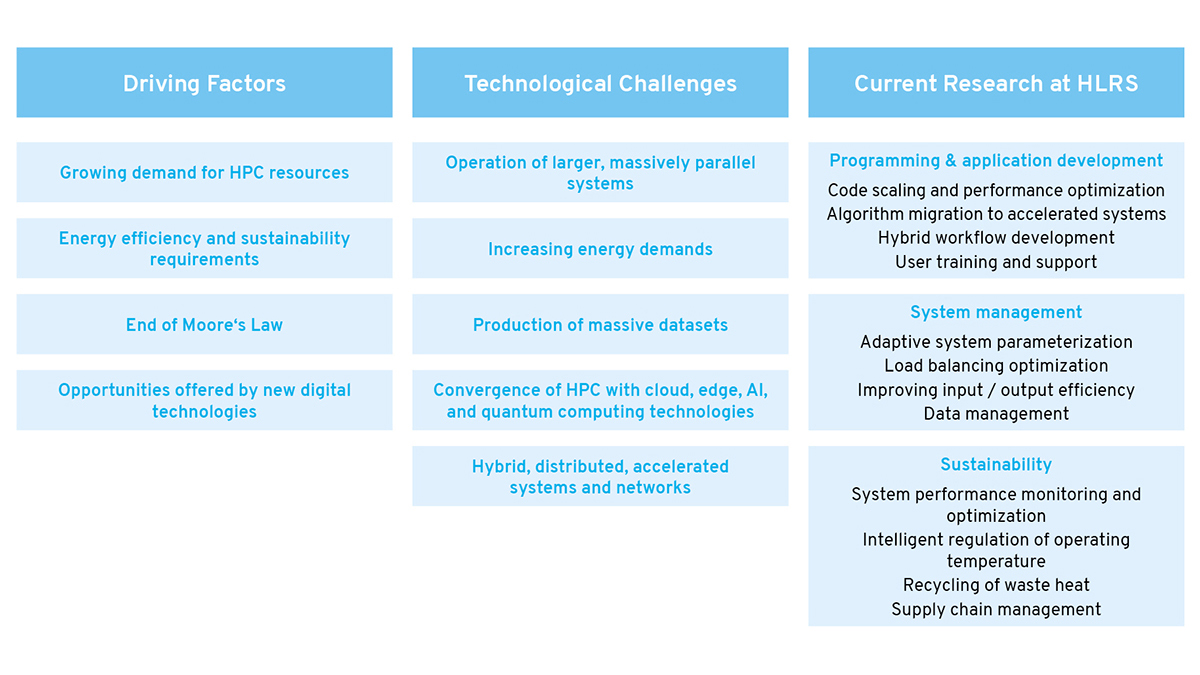
Achieving this lightning speed is not simply a matter of building larger machines, however. This is because the pre-exascale and exascale systems being developed today are fundamentally different from supercomputers of previous generations. Crucially, major increases in power are needed to run and cool systems of this size, meaning that maximizing energy efficiency in their operation and usage is more important than ever for ensuring their financial and environmental sustainability. Simultaneously, hardware manufacturers are reaching the physical limits of how much performance can be achieved on each individual computer chip, meaning that the progression predicted by Moore’s Law has basically run its course. At the system architecture level, this combination of factors means that whereas supercomputers of an earlier generation grew by simply adding larger numbers of central processing units (CPU), the new generation increasingly combines CPUs with purpose-built accelerators, which, in most cases, are based on graphic processing unit (GPU) technology. Such heterogeneous systems are faster and more energy efficient, but they also require new programming models and software to fully leverage their performance. This is not only because of the larger numbers of processors but also because, currently, many widely used software packages and scientific applications developed for CPU-only systems are hardly supported on accelerated systems, let alone optimized.
Compounding these challenges is the convergence of supercomputers with other digital technologies, leading to the development of increasingly hybrid computing systems and workflows. Sensors, edge and cloud computing, artificial intelligence, and quantum computing offer new opportunities for research, technology development, and public administration, but combining them effectively in ways that utilize their full power requires new programming workflows and systems operations. HPC is no longer just a matter of running a large simulation on a single supercomputer, but is increasingly becoming a complex, distributed process that must be coordinated among computers with different capabilities and programming requirements, often situated at different locations. Orchestrating the processes needed to get these technologies to talk to one another and to move data in a fast and secure way is demanding new approaches for managing tasks across such networks.
In addition, not all hardware components that are essential for high-performance computing are evolving at the same rate. Historically, for example, memory hardware has struggled to keep pace with accelerated systems, meaning that the writing and reading of data can still slow down large-scale simulations. Artificial intelligence (AI) is also changing key characteristics of scientific data. Whereas classical simulations used relatively few input data, AI requires the management of massive datasets composed of millions of small files, meaning that input and output in distributed file systems must be optimized for data processing. And although more processing speed permits more complex ensemble simulations or multiphysics models, for example, it also means generating ever-larger mountains of data. Archiving it for reuse in future studies, for training AI algorithms, or to double-check the results of a scientific paper threatens to overwhelm HPC centers, both because of the space and power requirements for data storage and the time required to backup or transfer large datasets.
“As high-performance computing continues to grow, it is changing in ways that present a host of new challenges,” says Prof. Dr. Michael Resch, director of HLRS. “As a federal high-performance computing center working within this emerging landscape, it is our job to provide the infrastructure, solutions, support, and training that will help scientists to navigate these changes, and ultimately to get answers to their complex questions efficiently and in a sustainable way.”
In several new research projects launched in late 2022 and early 2023, staff scientists at HLRS are creating and testing potential solutions to some of these big challenges facing HPC. Conducted in partnership with other leading HPC centers and industry, these projects will both contribute to the development of the field and ensure that HLRS continues to provide state-of-the-art support to its community of system users. These projects also offer a window for beginning to understand some of the ways in which high-performance computing and related fields will need to evolve in the coming years.
One advantage of larger HPC systems is that they make it possible to run simulations in which potentially billions of parallel calculations are executed simultaneously. In many simulations, for example in computational fluid dynamics (CFD) or climate modeling, programmers create a computational mesh that divides a large simulation into smaller units that are calculated individually and then reintegrated to understand the system as a whole. To use parallel computing systems most efficiently, programmers must adjust the distribution of these units based on the number and types of processing units that are available. As larger computers with hybrid architectures go online, the number of processing units rises, making it more difficult to achieve efficient performance using today’s algorithms. This means that for many conventional problems that scientists and engineers need to solve, taking full advantage of the speed that new exaflop-capable systems offer will not happen unless codes are scaled to meet them.
As a member of a new EuroHPC Joint Undertaking Centre of Excellence called CEEC (Center of Excellence for Exascale CFD), HLRS is working to improve state-of-the-art algorithms and methods used in computational fluid dynamics to ensure that they perform efficiently at exascale. The project aims to develop exascale-ready workflows for extremely large computing systems, implement methods for reducing the amount of the energy used to run these algorithms, and demonstrate these new algorithms’ effectiveness in applications that are important in academic and industrial research. The project is focusing on key algorithms for a variety of fields that rely on CFD simulations, including aeronautical engineering, environmental science, the chemical industry, the wind energy industry, and atmospheric sciences.
HLRS is also coordinator of the project EXCELLERAT, the European Centre of Excellence for Engineering Applications, which has been pursuing a related strategy to prepare industry for the next generation of high-performance computing. As a service provider, the project is supporting the development of key codes used in industrial sectors such as automotive, aerospace, and energy to run efficiently on larger, hybrid HPC systems. Research in the project has helped to adapt existing codes to run efficiently across dramatically larger numbers of processors, including on systems that include GPUs and other newer types of processors. The results have shown increases in processing speed of up to 90% as well as dramatic increases in simulation resolution, making it possible to show finer detail in simulations of airflow around airplane wings or in combustion reactions, for example. Near the end of 2022, EXCELLERAT was funded for a second project phase, and will continue to support industry in preparing for the next generation of HPC in the coming years.
HLRS continues to be involved in two additional EuroHPC Centres of Excellence that are focused on software for exascale computing and entered their second phases at the beginning of 2023. The first is ChEESE, which is developing exascale-ready codes for solid earth research that could support early warning forecasts, hazard assessment, and emergency responses to geohazards such as volcanoes, earthquakes, or tsunamis. The HiDALGO project, for which HLRS serves as technical coordinator, has also been extended, focusing on developing methods that could help to address global challenges using new, hybrid HPC systems.
In the past, a supercomputer’s energy usage could be limited using crude approaches such as reducing the clock frequency that controls processor speed or shutting off sections of the system when they were not in use. Modern HPC systems, however, offer a growing number of options that hold high energy savings potential. For example, adjusting parameters and settings in OpenMP and MPI — two important programming paradigms for parallel computing systems — can improve software performance, leading to more efficient energy usage. When multiple user applications are running on the system at the same time, system administrators can also track and optimize how those applications run in a more holistic, system-wide basis using MPI. Determining the optimal settings for such a systemic approach can be difficult, however, particularly when HPC systems simultaneously run many, diverse applications.
In a project called EE-HPC, HLRS is helping to develop and test a new approach initiated at the University of Erlangen-Nürnberg that aims to reduce energy consumption while maximizing computational throughput. Using machine learning, software will dynamically set system parameters to optimize energy usage in hardware based on the jobs and job phases that are running at any particular time. Bringing many years of experience as a member of the MPI-Forum, which sets standards for this widely used programming framework, HLRS will enable the integration of monitoring software into the runtime environment of OpenMP and MPI. A graphic user interface will also offer users transparent insights into the decisions the system is making while running their software.
In the project targetDART, HLRS is pursuing strategies to improve the scalability and energy efficiency of applications by optimizing load balancing. Here, the focus is on the programming interface OpenMP, which orchestrates the distribution and execution of computing tasks across a parallel computing system, preventing spikes in activity on some parts of the system while other parts sit idle. The challenge is that because computing tasks in parallelized simulations depend on the output of other tasks, data must constantly be physically moved around the computer, and the time it takes for processors to communicate with one another can slow down the system. On today’s largest supercomputers, optimizing load balancing is extremely difficult, and it becomes even more challenging in hybrid systems, particularly as the scale of the entire system and thus the number of components to be monitored and optimized increases. By pursuing new strategies for managing task-dependencies and for monitoring and evaluating the performance of applications, targetDART aims to address this problem. As a member of the MPI-Forum, HLRS will also distribute advances made during targetDART among the wider HPC community.
As supercomputers grow toward exascale, other kinds of digital technologies have also been evolving that could extend the usefulness of high-performance computing far beyond the walls of the traditional HPC center. Sensors of all kinds, for example, now collect measurements that serve as the foundation of new models and simulations. With edge computing, computational tasks can be distributed to sites where data is gathered, making it possible to make decisions faster. Even within HPC centers themselves, new workflows are needed to integrate simulation and data analysis, which run best on different computing architectures. Putting all of these pieces together is one major task that high-performance computing is currently facing.
Emblematic of the challenges of this diversifying landscape is a recently launched project called DECICE, which focuses on cloud and edge computing. Such architectures are relevant in domains such as smart cities, industrial automation, and data analytics, where new applications often involve specialized hardware that is located close to users. Integrating these devices with high-performance computers like HLRS’s Hawk will mean ensuring low latency and high security during data transmission, as well as location awareness across the network.

DECICE is testing new methods for unifying such distributed networks of devices with a central controlling cluster. HLRS scientists will use KubeEdge, a system derived from the open-source framework Kubernetes, which was designed for deploying, scaling, and managing applications in large-scale hybrid computing systems using so-called containers. DECICE will further develop KubeEdge, which brings Kubernetes’ containerized approach to edge computing, using an AI-based approach to assign jobs to the most suitable resources across a distributed system made up of different kinds of devices and processors. HLRS is providing HPC infrastructure for DECICE, as well as its expertise in cloud computing, HPC programming, and HPC system operation. It will lead a work package focused on developing an integrated framework for managing tasks in the cloud, edge, and HPC.
As the landscape of larger, hybrid HPC system architectures becomes more diverse, HLRS’s training program has also been changing to ensure that the center’s computing resources are used most effectively. In addition to its traditional menu of courses focusing on programming languages for scientific computing and parallel programming frameworks like MPI and OpenMP, the center expanded its offerings to include new courses on GPU programming, deep learning, and artificial intelligence in 2022. This included a training collaboration with hardware manufacturer NVIDIA, which involved “bootcamp” workshops that introduced the use of artificial intelligence in science and offered a deeper dive into scientific machine learning using physics-informed neural networks. Another course held in partnership with AMD provided specialized instruction in machine learning using the company’s Instinct GPUs. Additional new courses at HLRS focused on programming models for adapting existing codes to accelerated architectures, including a collaboration with INTEL focusing on oneAPI, SYCL2020, and OpenMP offloading.
Here as in many disciplines that must work together to prepare for the future of high-performance computing, adaptation is the key word, particularly as the field approaches the limits of what came before. Whether it be limits on energy supplies and natural resources, the physical limits of a traditional CPU chip, limits in the ability to manage the data that HPC systems now produce, or limits in the flexibility of codes written for older architectures, a wide spectrum of challenges is converging in ways that are forcing HPC to evolve into something new and potentially even more powerful. Through its research and training initiatives, HLRS aims to be a protagonist that helps to push this transformation forward.
— Christopher Williams
A member of the Gauss Centre for Supercomputing, HLRS is one of three German national centers for high-performance computing.