High-Performance Computing Center Stuttgart
Using the material on this web page requires to accept our terms and conditions of use.
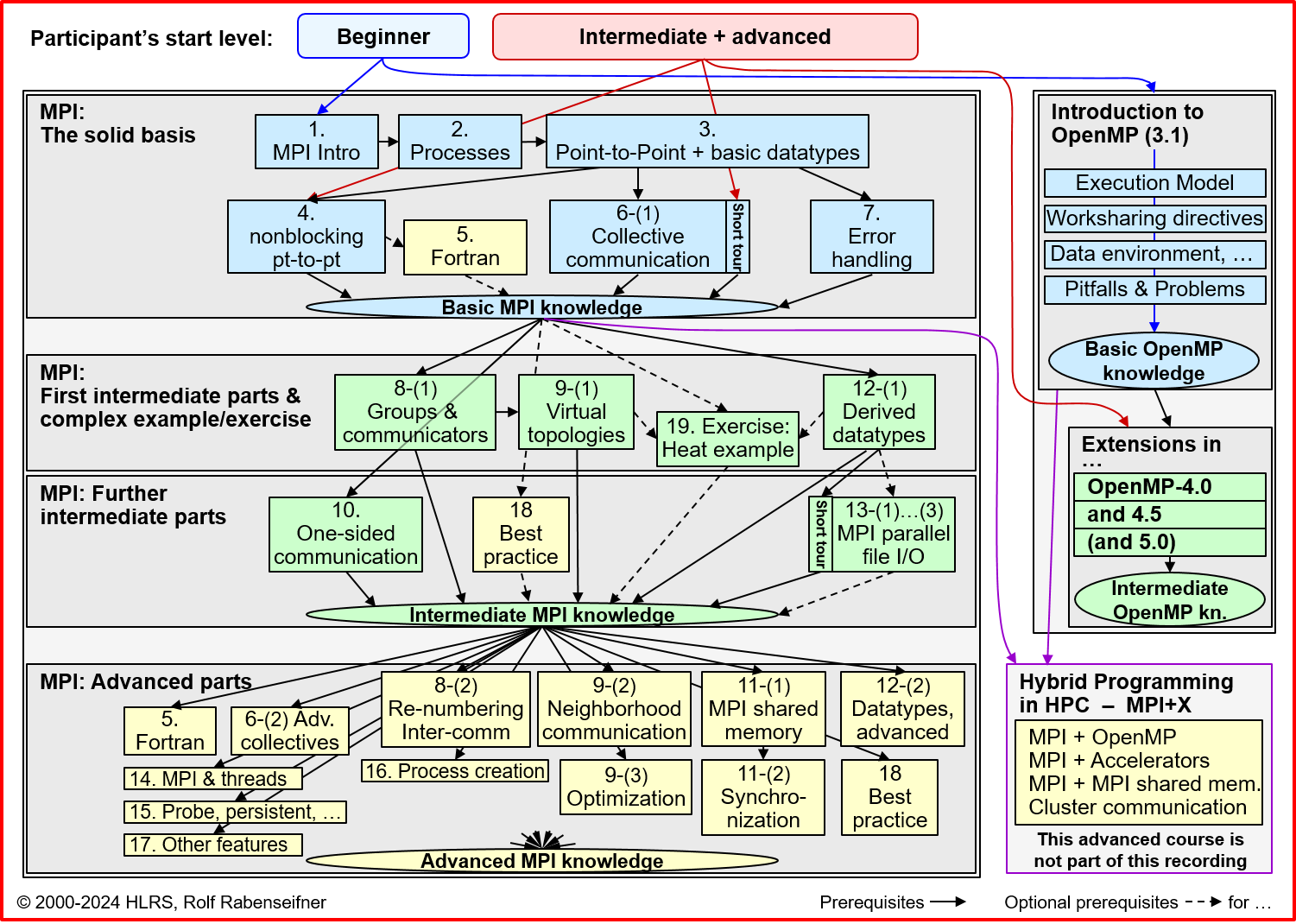
This web page is part of the HLRS self-study materials, which contains recordings of several courses, including the most recent recording of an MPI course based on the material shown here.
Highly recommended for MPI and OpenMP learning:
A structured study plan for the recorded material is available below.
The recorded material is useful for self-study of MPI and OpenMP.
However, for advanced parallelization (100+ cores), attending an on-site course
is highly recommended:
All of our MPI and OpenMP courses in on-site, online, and hybrid formats include labs and interaction with the instructor and each other:
Please visit https://www.hlrs.de/training
Slides: (please download, internal hyper-refs work best with Acrobat)
Content:
Exercises - please download (zip or tar.gz) and expand both MPI:
Your environment for the exercises:
To be able to do the hands-on exercises of this course, you need a computer with a C/C++ or Fortran compiler and a corresponding, up-to-date MPI library (in case of Fortran, the mpi_f08 module is required).
Please download TEST archive file TEST.tar.gz or TEST.zip
After uncompressing archive file via
tar -xvzf TEST.tar.gz
or unzip TEST.zip
please verify your MPI and OpenMP installation with the tests described in TEST/README.txt within the archive (or here).
Standards and API definitions:
Recordings:
A member of the Gauss Centre for Supercomputing, HLRS is one of three German national centers for high-performance computing.